Playing with OpenClip & ONNX
Published on
Lately I’ve been involved on implementing vector search at multiple e-commerce websites, a common challenge that always pops up is how to serve the encoder model that is responsible to translate the user query (text) into a vector (numbers).
While encoding text to vectors might seem a fairly simple task, doing this for search at a e-commerce comes with some challenges. First, we need to keep latency low as usually search results should be available within 500-1000ms and encoding the text is just one of the steps you need to do in a bigger pipeline. Second, search is probably one of the most used entry points by your customers, which means that we need to handle 100s or even 1000s of requests every second.
With this in mind, in this blogpost (and repo) we explore how the Clip text encoder behaves and try to make some optimizations to improve its latency and throughput. The Clip model is composed by a text encoder (a Roberta transformer) and a image encoder (a Vision transformer), since we are not interested in encoding images in the experiments we don’t use the ViT, in fact in some scenarios we even remove the ViT and deal only with the text encoder. While we do it here for simplicity, in a production scenario removing the ViT might be helpful to save you some memory.
We will try 4 different scenarios:
- [OpenCLIP](https://github.com/mlfoundations/open_clip raw implementation. We refer to this scenario as
mclip-openclip - OpenClip raw implementation with a custom tokenizer that doesn’t (always) pad input sequences to
max_size=77but instead just pad to the biggest sequence present in the batch. Tried this approach since we found that this was being the case with OpenClip. We refer to this scenario asmclip-openclip-custom-tokenizer - Load the OpenClip weights into a Hugging Face (HF) RoBERTa model. This implies that instead of the OpenClip implementation we will be using the HF implementation. We refer to this scenario as
roberta-hf - Same as 3. but we convert the model into ONNX format, and use the ONNX runtime at inference time. We refer to this scenario as
roberta-hf-onnx
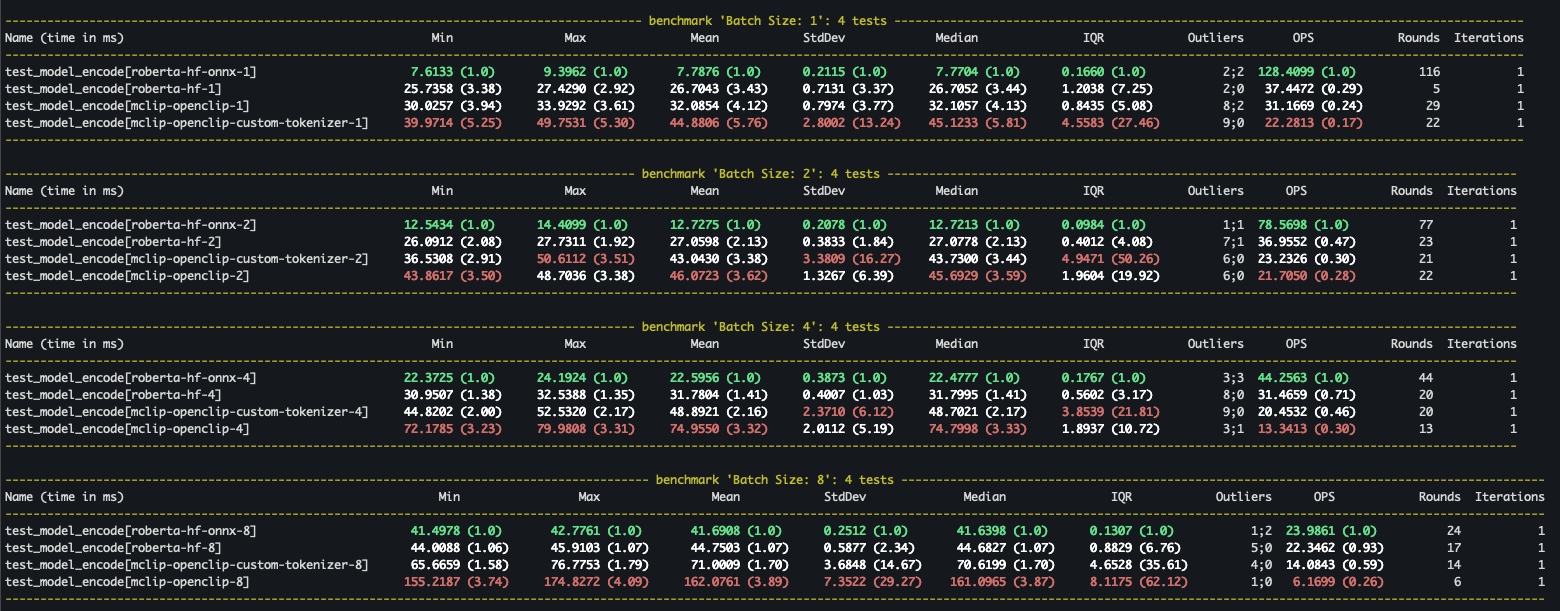
We putted all of these scenarios in a pytest-benchmark and we run it for the different scenarios always with the same input text: Example of a query to encode for vector search! {i} and with variable batch sizes ([1, 2, 4, 8]).
(NOTE: You can run the same benchmark, simply go to our repo and check the README instructions, in this case I ran it on Apple M3 Pro CPU)
The benchmark showed some interesting points:
- Using ONNX is always beneficial, mainly for smaller batches (why?).
- Converting to the HF model is always better than using the OpenClip implementation. To have a fair comparison we should compare
mclip-openclip-custom-tokenizerwithroberta-hfsince both of them do padding to the longest sequence in the batch. - Always look for details in the implementation, only after digging and finding out that the OpenClip library was always padding sequences to 77 tokens, we found out that it was one of the biggest bottlenecks. In a normal scenario (depending on your model architecture/implementation) there is no special reason why we would need to pad all sequences to max length all the time. In a search scenario on a website, most of the queries will typical not be that long.