Magic ENV variables for (Py)Torch models in K8s
Published on
With the proliferation of ML serving tools like TorchServe , SeldonMLServer or NvidiaTriton deploying torch models in Kubernetes (K8s) is the bread and butter for many ML engineers or Data Scientists out there.
Using these tools, an ML engineer’s task involves implementing a wrapper around the model to handle loading the model artifacts and typically providing a .predict method to process requests received by the web server endpoint.
Once this wrapper is complete and compatible with the tool, it’s usually packaged into a Docker image that can be deployed in K8s or any other container-based environment.
While these steps may seem straightforward, is it really that simple?
Can we achieve good performance by just following these steps? That’s what we’ll explore in this blog post ;)
TLDR: If your pods containing Torch models are constantly being throttled in K8s try:
- Set
MKL_NUM_THREADS,OMP_NUM_THREADSandOPENBLAS_NUM_THREADSenv variables to the number of cores specified in your K8s request spec. - Use
torch.set_num_threadsin your code and set it to the number of cores specified in your K8s request spec.
Setup
I tested a FashionCLIP model using TorchServe with a custom wrapper. This model receives an input str and returns a list[float] containing the embedding from the text encoder. The model and custom wrapper are bundled in the TorchServe format inside a Docker Image, which is served on K8s using CPU.
To test the service’s latency in K8s, I used the open-source tool Predator. This tool makes it easy to perform load testing and measure the service’s performance in terms of latency. For all tests, we set the CPU requests to 4 and the CPU limits to 5 in the K8s spec.
We tested 3 different scenarios for configuration:
- Default TorchServe config & no env variables: used the default TorchServe model config without setting any special environment variables.
- Default TorchServe config & env variables: used the default TorchServe model config and set the environment variables
MKL_NUM_THREADS=4,OMP_NUM_THREADS=4, andOPENBLAS_NUM_THREADS=4in the Docker container. We also set the Torch settingtorch.set_num_threads(4). - Tweaked TorchServe config & env variables: used the configuration from scenario 2 and added a custom TorchServe model config.:
minWorkers: 4
maxWorkers: 4
batchSize: 8
# in ms
maxBatchDelay: 10
# in seconds
responseTimeout: 1
Results & Conclusions
I tested three different load scenarios: 10 requests per second (rps), 50 rps, and 100 rps. For each scenario, I measured the median, p95, and p99 latencies. Additionally, I reported any errors (4xx/5xx) in the endpoint responses.
| scenario | load | median (ms) | p95 (ms) | p99 (ms) | response errors |
|---|---|---|---|---|---|
| 1. Default TorchServe config & no env variables | 10rps | 17.3 | 118.6 | 269.8 | no |
| 1. Default TorchServe config & no env variables | 50rps | 2716.2 | 3016.2 | 3177.2 | yes |
| 1. Default TorchServe config & no env variables | 100rps | 274.9 | 3027.1 | 3287.6 | yes |
| 2. Default TorchServe config & env variables | 10rps | 19.5 | 22.9 | 25.4 | no |
| 2. Default TorchServe config & env variables | 50rps | 18.2 | 21.2 | 26.6 | no |
| 2. Default TorchServe config & env variables | 100rps | 1737.0 | 1930.2 | 1997.1 | yes |
| 3. Tweaked TorchServe config & env variables | 100rps | 31.6 | 44.1 | 52.4 | no |
From this ablation, we can draw the following insights:
- The impact of configuration 1 vs. 2 is significant! Simply setting some environment variables increased our capacity from handling only 10 rps to 50 rps. A deeper analysis revealed that these variables prevented the pod from being constantly throttled, thereby improving overall throughput.
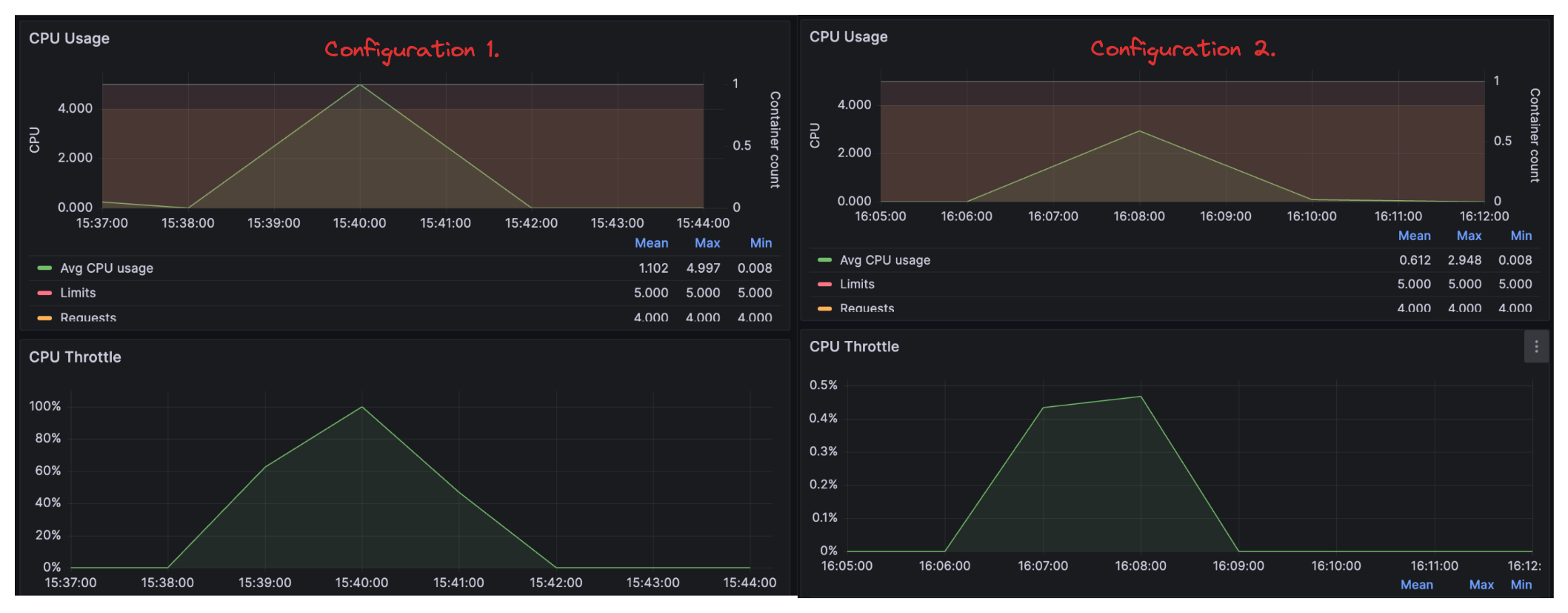
- We also see how leveraging TorchServe batching can save costs. With configuration 3, we handled around 100 rps at the expense of slightly increased latency. This is crucial, as it allows us to achieve more with the same hardware, translating to cost savings.
Hope you enjoyed, tanks for reading!